 PDF(4123 KB)
PDF(4123 KB)

Research on Robot Navigation Method Integrating Safe Convex Space and Deep Reinforcement Learning
DONGMingze, WENZhuanglei, CHENXiai, YANGJiongkun, ZENGTao
PDF(4123 KB)

Sponsored by: China Association for Science and Technology (CAST)
Editor-In-Chief: Xu Yida
ISSN 1000-1093
Hosted By: China Ordnance Society
Published By: Acta Armamentarii
CN 11-2176/TJ
PDF(4123 KB)
Research on Robot Navigation Method Integrating Safe Convex Space and Deep Reinforcement Learning
A robot navigation method based on deep reinforcement learning (DRL) is proposed for navigating the a robot in the scenario where the global map is unknown and there are dynamic and static obstacles in the environment. Compared to other DRL-based navigation methods applied in complex dynamic environment, the improvements in the designs of action space, state space, and reward function are introduced into the proposed method. Additionally, the proposed method separates the control process from neural network, thus facilitating the simulation research to be effectively implemented in practice. Specifically, the action space is defined by intersecting the safe convex space, calculated from 2D Lidar data, with the kinematic limits of robot. This intersection narrows down the feasible trajectory search space while meeting both short-term dynamic obstacle avoidance and long-term global navigation needs. Reference points are sampled from this action space to form a reference trajectory that the robot follows using a model predictive control (MPC) algorithm. The method also incorporates additional elements such as safe convex space and reference points in the design of state space and reward function. Ablation studies demonstrate the superior navigation success rate, reduced time consumption, and robust generalization capabilities of the proposed method in various static and dynamic environments.
mobile robot navigation / deep reinforcement learning / safe convex space / model predictive control / dynamic unknown environment {{custom_keyword}} /

Table 1 Staged training environment parameter settings表1 分阶段训练环境设计表 |
| 阶段 | 环境 尺寸/m | 静态障碍 物个数 | 动态障碍 物个数 | 动态障碍 物半径/m | 动态障碍物 速度/(m·s-1) |
|---|---|---|---|---|---|
| 1 | 20×30 | 0 | 0 | ||
| 2 | 20×30 | 10 | 0 | ||
| 3 | 20×30 | 10 | 5 | 0.2~0.3 | 0.3 |
| 4 | 20×30 | 10 | 10 | 0.2~0.3 | 0.3 |
| 5 | 10×10 | 0 | 10 | 0.1~0.4 | 0.3~0.6 |
| 6 | 10×10 | 0 | 20 | 0.1~0.4 | 0.3~0.6 |
| 7 | 10×10 | 0 | 30 | 0.1~0.4 | 0.3~0.6 |
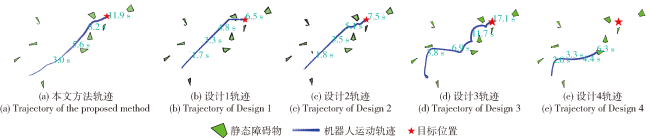
Table 2 Stage 2 scenario navigation performance metrics statistics表2 阶段2场景导航性能指标统计表 |
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||||||||||||||
| 设计1 | 76.0 | 4.0 | 2.2 | 11.3 | 6.3 | 2.9 | 0.3 | 0 | 1.0 | -0.6 | 11.8 | ||||||||||||
| 设计2 | 76.0 | 4.0 | 2.2 | 11.3 | 6.3 | 2.8 | 0.2 | 0 | 1.5 | -0.1 | 22.5 | ||||||||||||
| 设计3 | 90.3 | 9.0 | 5.2 | 15.2 | 8.3 | 2.8 | 0.2 | 0.3 | 1.9 | -0.1 | 7.0 | ||||||||||||
| 设计4 | 83.0 | 5.0 | 2.6 | 11.7 | 6.3 | 2.2 | 0.4 | 0.5 | 1.3 | -0.2 | 4.8 | ||||||||||||
| 本文方法 | 89.2 | 5.0 | 2.6 | 12.2 | 6.6 | 2.2 | 0.4 | 0.3 | 1.4 | -0.5 | 4.0 | ||||||||||||
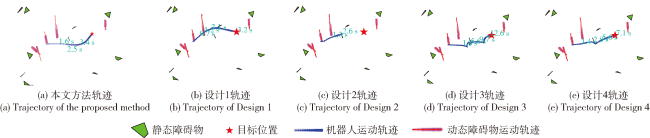
Table 3 Stage 3 scenario navigation performance metrics statistics表3 阶段3场景导航性能指标统计表 |
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||
| 设计1 | 80 | 4.0 | 2.2 | 11.4 | 6.2 | 2.9 | 0.3 | -0.1 | 1.3 | -0.1 | 16.9 |
| 设计2 | 79 | 4.0 | 2.1 | 11.4 | 6.2 | 2.9 | 0.2 | -0.1 | 2.2 | 0.0 | 35.9 |
| 设计3 | 88 | 8.8 | 5.0 | 15.4 | 8.6 | 1.8 | 0.4 | 0.3 | 1.8 | -0.1 | 6.6 |
| 设计4 | 84 | 4.9 | 2.4 | 11.6 | 6.3 | 2.2 | 0.4 | 0.5 | 1.3 | -0.3 | 4.9 |
| 本文方法 | 89 | 5.9 | 3.3 | 13.0 | 7.3 | 2.2 | 0.4 | 0.3 | 1.4 | -0.5 | 4.2 |
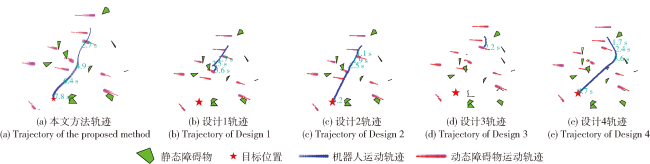
Table 4 Stage 4 scenario navigation performance metrics statistics表4 阶段4场景导航性能指标统计表 |
| 方法 | 成功率/% | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | ||
| 设计1 | 81 | 3.9 | 2.2 | 11.2 | 6.5 | 2.9 | 0.3 | -0.1 | 1.7 | -0.4 | 24.7 |
| 设计2 | 75 | 3.8 | 2.2 | 10.8 | 6.3 | 2.9 | 0.3 | -0.1 | 2.1 | 0.4 | 32.9 |
| 设计3 | 85 | 9.0 | 5.4 | 15.1 | 8.7 | 1.7 | 0.4 | 0.3 | 1.8 | -0.1 | 6.5 |
| 设计4 | 84 | 4.8 | 2.5 | 11.5 | 6.5 | 2.2 | 0.4 | 0.6 | 1.3 | -0.3 | 4.8 |
| 本文方法 | 86 | 5.8 | 3.3 | 12.5 | 7.1 | 2.1 | 0.4 | 0.3 | 1.4 | -0.5 | 4.3 |
Table 5 Reward functions rt1 and rt2 navigation performance statistics in the scenarios at Stages 5 to 7表5 rt1和rt2阶段5~阶段7场景下导航性能统计表 |
| 奖励函数 | 阶段 | 成功率 | 导航时间/s | 导航路程/m | 速度/(m·s-1) | 加速度/(m·s-2) | 加加速度/(m·s-3) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | 均值 | 标准差 | |||
| 5 | 87 | 2.8 | 1.6 | 4.6 | 2.5 | 1.6 | 0.4 | 0.6 | 1.4 | -0.9 | 4.1 | |
| rt1 | 6 | 77 | 2.8 | 1.8 | 4.1 | 2.4 | 1.4 | 0.4 | 0.6 | 1.4 | 1.4 | 4.1 |
| 7 | 68 | 3.1 | 2.1 | 4.2 | 2.5 | 1.4 | 0.4 | 0.5 | 1.3 | -0.7 | 4.3 | |
| 5 | 87 | 2.9 | 1.7 | 4.6 | 2.5 | 1.6 | 0.4 | 0.6 | 1.4 | -0.9 | 4.0 | |
| rt2 | 6 | 75 | 3.0 | 1.8 | 4.3 | 2.4 | 1.5 | 0.4 | 0.6 | 1.4 | -0.8 | 4.2 |
| 7 | 65 | 2.9 | 2.0 | 3.9 | 2.2 | 1.4 | 0.4 | 0.6 | 1.3 | -0.8 | 4.2 | |
| [1] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [2] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [3] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [4] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [5] |
王霄龙, 陈洋, 胡棉, 等. 基于改进深度Q网络的机器人持续监测路径规划[J]. 兵工学报, 2024, 45(6):1813-1823.
持续监测问题指的是通过规划移动机器人在路网中的巡逻路线,从而对路网环境实施长期监测,以实现保障环境安全的目的。环境中的待监测点通常受到最大允许监测周期(重访周期)的限制,并且最优的监测路径不应具有固定的周期,否则监测过程容易被恶意入侵者针对性地破坏。针对上述问题,提出一种基于改进深度Q网络(Deep Q Networks, DQN)的机器人监测路径规划算法。改进DQN的决策方法,使机器人获得一条监测频率高、安全性好(防止被智能入侵的能力)、非固定周期的监测路径。仿真实验结果表明:所提算法可以高效地覆盖所有待监测节点;与传统的DQN算法相比,该算法不会使监测陷入周期性的循环路径之中,增强了系统的抗入侵能力。
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [6] |
董豪, 杨静, 李少波, 等. 基于深度强化学习的机器人运动控制研究进展[J]. 控制与决策, 2022, 37(2):278-292.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [7] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [8] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [9] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [10] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [11] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [12] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [13] |
黄昱洲, 王立松, 秦小麟. 一种基于深度强化学习的无人小车双层路径规划方法[J]. 计算机科学, 2023, 50(1):194-204.
随着智能无人小车的广泛应用,智能化导航、路径规划和避障技术成为了重要的研究内容。文中提出了基于无模型的DDPG和SAC深度强化学习算法,利用环境信息循迹至目标点,躲避静态与动态的障碍物并且使其普适于不同环境。通过全局规划和局部避障相结合的方式,该方法以更好的全局性与鲁棒性解决路径规划问题,以更好的动态性与泛化性解决避障问题,并缩短了迭代时间;在网络训练阶段结合PID和A<sup>*</sup>等传统算法,提高了所提方法的收敛速度和稳定性。最后,在机器人操作系统ROS和仿真程序gazebo中设计了导航和避障等多种实验场景,仿真实验结果验证了所提出的兼顾问题全局性和动态性的方法具有可靠性,生成的路径和时间效率有所优化。
With the wide application of intelligent unmanned vehicles,intelligent navigation,path planning and obstacle avoidance technology have become important research contents.This paper proposes model-free deep reinforcement learning algorithms DDPG and SAC,which use environmental information to track to the target point,avoid static and dynamic obstacles,and can be generally suitable for different environments.Through the combination of global planning and local obstacle avoidance,it solves the path planning problem with better globality and robustness,solves the obstacle avoidance problem with better dynamicity and generalization,and shortens the iteration time.In the network training stage,PID,A<sup>*</sup> and other traditional algorithms are combined to improve the convergence speed and stability of the method.Finally,a variety of experimental scenarios such as navigation and obstacle avoidance are designed in the robot operating system ROS and the simulation program gazebo.Simulation results verify the reliability of the proposed approach,which takes the global and dynamic nature of the problem into account and optimizes the generated paths and time efficiency.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [14] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [15] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [16] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [17] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [18] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [19] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [20] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [21] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [22] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [23] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [24] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| [25] |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
PDF(4123 KB)
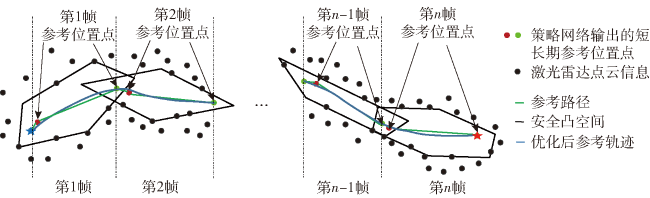
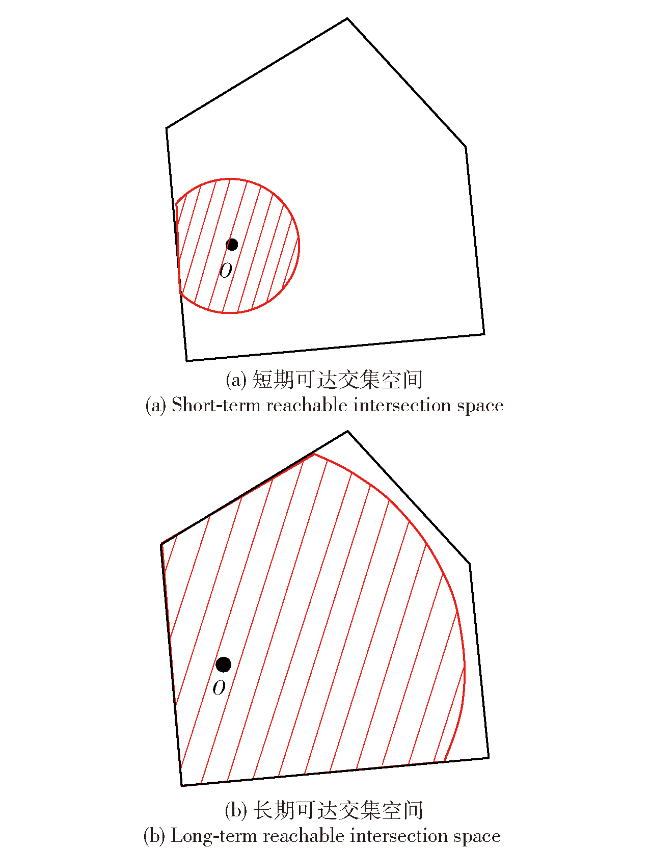
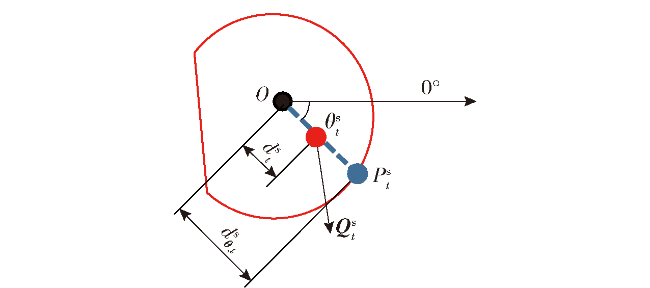
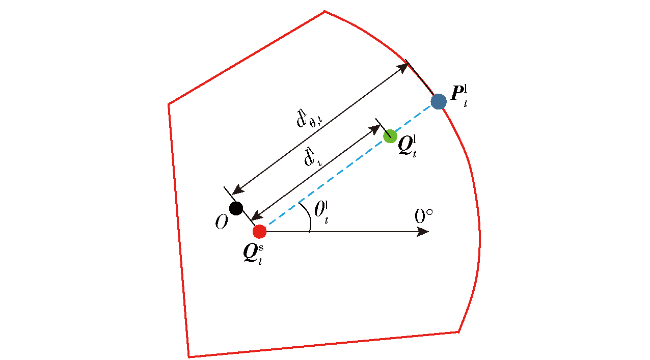
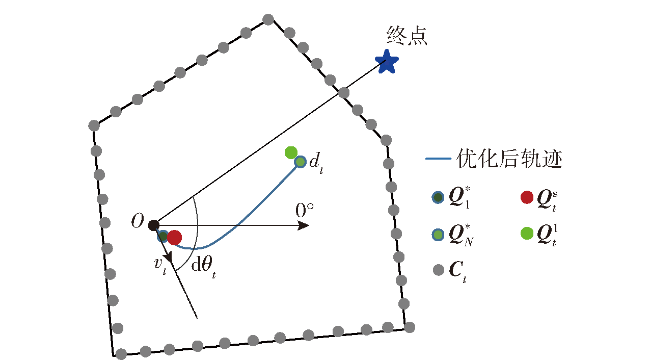
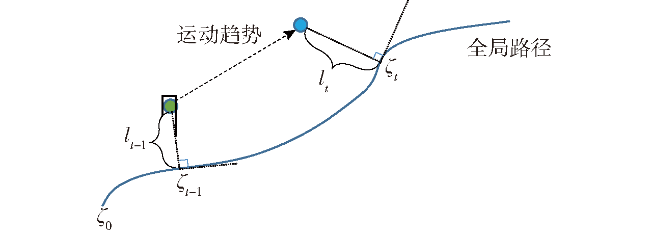
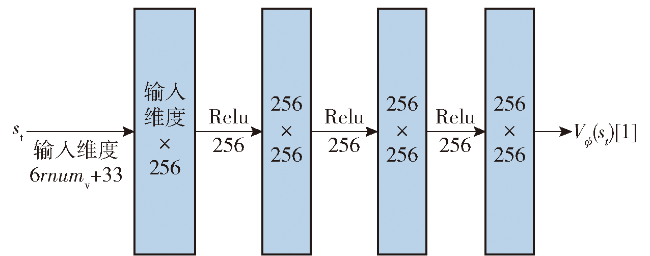
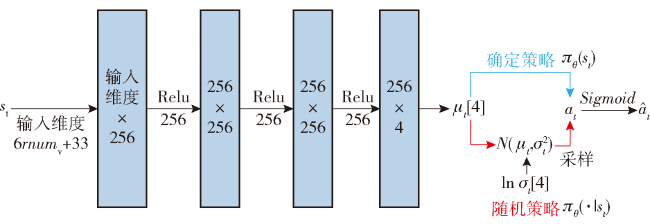
 Fig.1 Iterative solution procedureFig.2 Short-term and long-term reachable intersection spacesFig.3 Short-term reference position calculationFig.4 Long-term reference position calculationFig.5 Schematic diagram of state-space observationsFig.6 Schematic diagram of potential energy shaping reward based on global pathFig.7 Design of state value networkFig.8 Design of strategy network
Fig.1 Iterative solution procedureFig.2 Short-term and long-term reachable intersection spacesFig.3 Short-term reference position calculationFig.4 Long-term reference position calculationFig.5 Schematic diagram of state-space observationsFig.6 Schematic diagram of potential energy shaping reward based on global pathFig.7 Design of state value networkFig.8 Design of strategy network Table 1 Staged training environment parameter settingsTable 2 Stage 2 scenario navigation performance metrics statisticsFig.9 Demonstration of the navigation results of different methods in Stage 2 scenarioTable 3 Stage 3 scenario navigation performance metrics statisticsFig.10 Demonstration of the navigation results of different methods in Stage 3 scenarioTable 4 Stage 4 scenario navigation performance metrics statisticsFig.11 Demonstration of the navigation results of different methods in Stage 4 scenarioTable 5 Reward functions rt1 and rt2 navigation performance statistics in the scenarios at Stages 5 to 7
Table 1 Staged training environment parameter settingsTable 2 Stage 2 scenario navigation performance metrics statisticsFig.9 Demonstration of the navigation results of different methods in Stage 2 scenarioTable 3 Stage 3 scenario navigation performance metrics statisticsFig.10 Demonstration of the navigation results of different methods in Stage 3 scenarioTable 4 Stage 4 scenario navigation performance metrics statisticsFig.11 Demonstration of the navigation results of different methods in Stage 4 scenarioTable 5 Reward functions rt1 and rt2 navigation performance statistics in the scenarios at Stages 5 to 7/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}